JAVA容器相关知识点整理
简介
- 整理容器的基本知识
- 整理关于不同容器线程安全方面的知识
根据以下资料整理
http://www.jianshu.com/p/047e33fdefd2
http://blog.csdn.net/jiyiqinlovexx/article/details/51030720
常用容器关系图

快速了解
Collection(接口)
- 代表的是单个元素对象的序列,(可以有序/无序,可重复/不可重复 等,具体依据具体的子接口Set,List,Queue等);
- 调用
toArray(T[] a)可以转为数组 - 区别于
java.util.Collections:Collections是一个正对于Conllection的工具类,提供了许多实用的静态方法
Map(接口)
- 代表的是“键值对”对象的集合(同样可以有序/无序 等依据具体实现)
- 提供了三种遍历方式:
Set<K> keySet(): 返回所有key的Set集合Collection<V> values(): 返回所有values的集合Set< Map.Entry< K, V>> entrySet(): 是将整个Entry对象(也就是返回键-值形式的集合)作为元素返回所有的数据,这种方式比先通过keySet()获取所有key再根据key获取值效率要高
List(Collection的子接口)
- 一个有序的Collection(或者叫做序列)。使用这个接口可以精确掌控元素的插入,还可以根据index获取相应位置的元素。
- 可重复
- 有顺序
- 提供了特殊的iterator遍历器,叫做
ListIterator。这种遍历器允许遍历时插入,替换,删除,双向访问。 并且还有一个重载方法允许从一个指定位置开始遍历。
ArrayList(List接口的实现)
- ArrayList是一个实现了List接口的可变数组
- 可以插入null
- 它的size, isEmpty, get, set, iterator,add这些方法的时间复杂度是O(1),如果add n个数据则时间复杂度是O(n).
- ArrayList不是synchronized的。
LinkedList(List接口的实现)
- LinkedList是一个链表维护的序列容器。和ArrayList都是序列容器,一个使用数组存储,一个使用链表存储。
- 数组和链表2种数据结构的对比:
- 查找方面。数组的效率更高,可以直接索引出查找,而链表必须从头查找。
- 插入删除方面。特别是在中间进行插入删除,这时候链表体现出了极大的便利性,只需要在插入或者删除的地方断掉链然后插入或者移除元素,然后再将前后链重新组装,但是数组必须重新复制一份将所有数据后移或者前移。
- 在内存申请方面,当数组达到初始的申请长度后,需要重新申请一个更大的数组然后把数据迁移过去才行(
所以当创建ArrayList,最好能给一个合理的初始大小)。而链表只需要动态创建即可。 - LinkedList还实现了Deque接口,Deque接口是继承Queue的。所以LinkedList还支持队列的pop,push,peek操作

Set(Collection的子接口)
- 存储不重复的元素集合
HashSet(Set接口的实现)
- 基于HashMap进行存储(所以所有的add,remove等操作其实都是HashMap的add、remove操作。遍历操作其实就是HashMap的keySet的遍历)
- 不保证顺序,且不保证下次遍历的顺序和之前一样
- 允许null元素
LinkedHashSet(Set接口的实现)
- 基于LinkedHashMap
- 相对于HashSet来说就是一个可以保持顺序的Set集合
TreeSet(Set接口的实现)
- 基于TreeMap
- TreeSet内的元素必须实现Comparable接口
- 一组有次序的集合,如果没有指定排序规则Comparator,则会按照自然排序。(自然排序即e1.compareTo(e2) == 0作为比较)

Queue(Collection的子接口)
Map
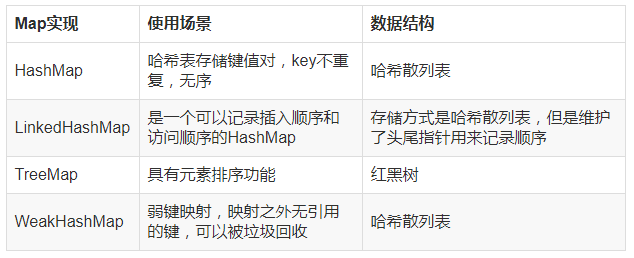
HashMap
- 最基础最常用的一种Map,它无序,以散列表的方式进行存储
LinkedHashMap
- 相对于HashMap来说区别是,LinkedHashMap遍历的时候具有顺序,可以保存插入的顺序,(还可以设置最近访问的元素也放在前面,即LRU)
- 其实LinkedHashMap的存储还是跟HashMap一样,采用哈希表方法存储,只不过LinkedHashMap多维护了一份head,tail链表。
TreeMap
- TreeMap平时用的不多,TreeMap会实现SortMap接口,定义一个排序规则,这样当遍历TreeMap的时候,会根据规定的排序规则返回元素。
WeakHashMap
- 特点是,当除了自身有对key的引用外,此key没有其他引用那么此map会自动丢弃此值
以上,感谢http://www.jianshu.com/p/047e33fdefd2 ,如有冒犯,请联系我删除
关于容器的线程安全
同步容器类
JDK1.0开始有两个很老的同步容器类:Vector和HashTable
JDK1.2之后Collections工具类中添加了一些工厂方法返回类似的同步封装器类:Collections.synchronizedXXX(XXX xxx)
实现方式:
将它们的状态封装起来,并对每一个公有方法进行同步。
其中Vector就是Object[]+synchronized方法,Hashtable是HashtableEntry[]+synchronized方法。而synchronizedXXX()方法返回的同步封装器类更是简单地将传进来的Collection的所有方法封装为synchronized方法而已。
缺点:
- 通过同步方法将访问操作串行化,导致并发环境下效率低下
- 复合操作(迭代、条件运算如没有则添加等)非线程安全,需要客户端代码来实现加锁。
并发容器类
并发容器出现的最大的需求就是提升同步容器类的性能!
可以对比(非并发容器类)看看,将单线程版本和并发版本做一个比较。
HashMap和HashSet的并发版本
ConcurrentHashMap<K, V>(HashMap的并发版本)
版本:JDK5
目标:代替Hashtable、synchronizedMap,支持复合操作
原理:采用一种更加细粒度的加锁机制“分段锁”,任意数量读取线程可以并发读取,任意数量的读取线程和一个写线程可以并发访问,一定数量的写入线程可以并发访问。并发环境下ConcurrentHashMap带来了更高的吞吐量,而在单线程环境下只损失了很小的性能。CopyOnWriteArraySet<E>(HashSet的并发版本)
版本:JDK5
目标:代替synchronizedSet
原理:CopyOnWriteArraySet基于CopyOnWriteArrayList实现,其唯一的不同是在add时调用的是CopyOnWriteArrayList的addIfAbsent方法,其遍历当前Object数组,如Object数组中已有了当前元素,则直接返回,如果没有则放入Object数组的尾部,并返回。
TreeMap和TreeSet的并发版本
ConcurrentSkipListMap<K, V>(TreeMap的并发版本)
版本:JDK6
目标:代替synchronizedSortedMap(TreeMap)
原理:Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。Skip list让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,通过”空间来换取时间”的一个算法。ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,在理论上能够在O(log(n))时间内完成查找、插入、删除操作。ConcurrentSkipListSet<E>(TreeSet的并发版本)
版本:JDK6
目标:代替synchronizedSortedSet
原理:内部基于ConcurrentSkipListMap实现!
ArrayList和LinkedList的并发版本
CopyOnWriteArrayList<E>(ArrayList的并发版本)
目标:代替Vector、synchronizedList
原理:CopyOnWriteArrayList的核心思想是利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。ConcurrentLinkedQueue<E>(LinkedList的并发版本)
目标:代替Vector、synchronizedList
特点:基于链表实现的FIFO队列,特别注意单线程环境中LinkedList除了可以用作链表,也可用作队列,并发版本也一样
阻塞队列:BlockingQueue
版本:JDK1.5
特点:拓展了Queue,增加了可阻塞的插入和获取等操作
实现类LinkedBlockingQueue:基于链表实现的可阻塞的FIFO队列ArrayBlockingQueue:基于数组实现的可阻塞的FIFO队列PriorityBlockingQueue:按优先级排序的队列
原理:通过ReentrantLock实现线程安全,通过Condition实现阻塞和唤醒。
以上,感谢http://blog.csdn.net/jiyiqinlovexx/article/details/51030720 ,如有冒犯,请联系我删除
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!